
Úloha 6 - Problém vážené splnitelnosti booleovské formule
Autor: Petr Chytil
Je dána booleovská
formule F proměnných X=(x1,
x2, ... , xn) v
konjunktivní normální formě (tj. součin
součtů). Dále jsou dány celočíselné
kladné váhy W=(w1, w2,
... , wn). Najděte ohodnocení
Y=(y1, y2, ... , yn)
proměnných x1, x2, ... ,
xn tak, aby F(Y)=1 a součet
vah proměnných, které jsou ohodnoceny jedničkou,
byl maximální.
Je přípustné
se omezit na formule, v nichž má každá formule právě
3 literály (problém 3 SAT). Takto omezený
problém je stejně těžký, ale možná se lépe
programuje a lépe se posuzuje obtížnost instance (viz
Selmanova prezentace v odkazech).
Simulované ochlazování se na rozdíl od genetických algoritmů inspirovalo ve fyzice. Jedná se tak o simulaci ochlazování zahřátého kovu. Kmitání zahřátých částic pro nás představuje možnost vyskočit z aktuálního řešení do řešení v okolí, jehož velikost je dána teplotou. Vyšší teplota znamená větší rozkmit a skoky do vzdálenějších řešení. S klesající teplotou se rozkmit zmenšuje, až se zastaví zcela a algoritmus „zamrzne“ na konečném řešení.
Důležitou součástí použití tohoto algoritmu je nastavení všech počátečních parametrů. Jedná se o počáteční teplotu, konečnou teplotu (po jejím dosažení se nepokračuje) a koeficient ochlazování. Posledním parametrem je pak délka vnitřní smyčky, která určuje, jak dlouho algoritmus hledá nejlepší stav na aktuální teplotě.
Specifika nasazení SA na 3 SAT
Vyřešit pomocí tohoto algoritmu problém 3 SAT znamenalo v první řadě implementovat metodu nextState (v kódu níže je vidět, kde je volána). Ta vrací souseda, který ještě vyhovuje aktuální teplotě algoritmu. Soused je stav se stejným ohodnocení proměnných, které se liší od aktuálního stavu ohodnocením právě jedné proměnné.
Oproti problému batohu bylo třeba změnit též metodu better(). Ta vrací lepší ze dvou stavů na základě jejich váhy. K tomu však přidává kontrolu splnitelnosti formule. Nedovolí tak nastavit jako nejlepší nesplnitelný stav, pokud je současný stav splnitelný. To však nemá vliv na procházení stavového prostoru, ale pouze na to, který stav bude ve finále označen za nejlepší.
Kód kostry algoritmu (dle slidů na cvičení):
public State simulatedAnnealing(State initState){
temp = initTemp;
state = initState;
best = state;
do {
steps = initSteps;
do {
state = nextState(state, temp);
best = better(best, state);
} while (!equilibrium());
temp = cool(temp);
} while (!frozen());
return best;
}
Zdrojové kódy celého řešení v jazyce java jsou tradičně k nahlédnutí v adresáři src. Z počátku jsem vyrobil nezbytnou objektovou podporu pro tento problém. Pak jsem ale pro urychlení vytvořil množství globálních a statických proměnných, které vedly k ne zrovna čitelnému a přehlednému kódu. Program je rozdělen na tři části:
SAT_SA.java - Vlastní algoritmus.
SAMeasure.java – Program sloužící ke „krmení“ výše zmíněného algoritmu instancemi s různymi parametry SA.
WeightGenerator.java – Generátor vah. Ze souborů v DIMACS cnf soubory vyrábí soubory podobné, které navíc obsahují váhy a používají se jako zadání instance pro algoritmus.
Export sešitu z Excelu, který byl použit pro některé výpočty a tvorbu grafů je v souboru vypocty.
Instance použité pro měření
Použil jsem instance v DIMACS cnf formátu z této stránky. A to konkrétně ty nejjednodušší – 20 instancí a 91 klauzulí. Pro generováni vah jsem napsal jednoduchý generátor, který pro každou proměnnou vybere náhodné přirozené kladné číslo v hodnotě od 1 do 100. Seznam těchto vah uloží do souboru, který je až na tyto váhy shodný s původním cnf formátem. Váhy jsou uloženy jako seznam čísel oddělených mezerou. Řádek s tímto seznamem je uvozen písmenem w a je v souboru umístěn mezi řádek uvozený p a samotnou formuli. Takový soubor pak má pak před koncovkou příponu „_w“.
Počáteční parametry
Pro hledání parametrů jsem zvolil 100 instancí z výše uvedené stránky, ke kterým jsem vygeneroval váhy proměnných. Při měření jsem sledoval průměrné hodnoty z tohoto souboru instancí, protože jsem se chtěl vyhnout situaci, ve které bych nalezl vhodné parametry algoritmu, který by ve finále „slušně“ řešil třeba jen jedinou instanci. Pozoroval jsem hlavně tyto výstupní hodnoty:
procento nalezených splnitelných řešení
průměrná cena instance (pokud bylo nalezeno splnitelné řešení)
průměrný čas nalezení řešení (pokud bylo nalezeno splnitelné řešení)
Jako počáteční vstupní parametry jsem volil hodnoty řádově shodné s těmi, které byly použity pro řešení problémem batohu:
počáteční teplota = 1000
konečná teplota = 3
počet kroků = 10000
faktor ochlazování = 0.8
Hledání nového parametru
Nejvíce času jsem věnoval počátečnímu hledání nového parametru a vztahu, kterým by se podílel na odmítání nesplnitelných stavů. To je novinka oproti problému batohu. Tam jsem se stavům, ve kterých je batoh přeplněný, nevěnoval vůbec.
Jak jsou na tom naše instance se splnitelností? Max SAT.
Nejprve jsem implementoval algoritmus řešící MAX SAT problém, abych zjistil, jsou-li vůbec zvolené úlohy řešitelné. A pokud ano, tak s jakou úspěšností. Musel jsem tedy upravit metodu nextState() tak, aby mi vracela náhodného souseda a počítala při tom s počtem splnitelných klauzulí v aktuálním stavu a v tom novém, náhodném. Přikládám zlomek kódu, který rozhodoval o tom, jestli bude nový stav (newState – náhodně vygenerovaný soused) přijat, či nikoliv.
delta = (double)state.numOfSatisfiableClauses() / newState.numOfSatisfiableClauses();
if (delta > 1) {
double r;
r = random.nextDouble();
if (r < Math.exp(-( (delta) / temp))) {
state = newState;
}
} else {
state = newState;
}
return state;Rozhodnutí o tom, jestli je vrácený stav lepší než aktuální best stav se dělo čistě na základě počtu splnitelných klauzulí ve formuli. Nalezení splnitelné formule pro mou implementaci simulovaného ochlazování naštěstí nebyl velký problém.
Splnitelnost nestačí – řešíme váženou splnitelnost 3 SAT.
S tímto požadavkem kromě algoritmu ochladlo i mé nadšení, když jsem změnil hodnotu proměnné delta tak, aby obsahovala rozdíl vah řešení jak jej vyžaduje problém splnitelnosti vážené formule:
delta = (double)state.weight() / newState.weight();
Spolu s tím jsem změnil i vyhodnocování best stavu tak, aby byl nejlepší vyhodnocen na základě své váhy. Algoritmus se tak sice snažil najít stavy s nejvyšší váhou, ale často byly výsledkem nesplnitelné formule. Výsledkem byl strastiplný proces hledání vhodného parametru, který by kombinoval oba výše zmíněné problémy a přispěl by tak k nalezení splnitelného stavu s co nejvyšší váhou. To bylo obtížné hlavně z toho důvodu, že jsem nevěděl, zda jsou ostatní počáteční parametry nastaveny vhodně pro řešení tohoto problému. Napsal jsem tedy další část programu, která krmila algoritmus instancemi a pouštěla řešení s různými parametry. Snažil jsem se všemožně manipulovat s hodnotou proměnné delta pokud měl být přijat nevhodný stav, abych snížil či zvýšil pravděpodobnost přijetí takového stavu. Bohužel měření stále ztroskotávala na tom, že změna, která se měla pozitivně projevit v počtu splněných instancí, byla přebita výkyvy v řešení, které byly způsobeny náhodnou volbou proměnné, s kterou je pak delta porovnávána. Tato náhodná proměnná se v algoritmu stará o to, aby horší stavy byly přijímány jen s určitou pravděpodobností. Toto snažení tedy nevedlo k nalezení parametru, jehož hodnota by byla prokazatelně spjata s počtem nalezených splnitelných formulí. Vedlo však k postupnému upravování metod nextState() a better() až do finálního stavu, kdy algoritmus pracuje uspokojivě a je možné měřit závislosti zbylých parametrů. Jejich změna už vyvolává měřitelné a vysvětlitelné změny ve výsledcích. Metoda better() vykrystalizovala do této podoby:
public State better(State state, State best) {
if (state.satisfiable()) {
if (best.satisfiable()) {
if (state.weight() > best.weight()) {
return state;
} else {
return best;
}
} else {
return state;
}
} else {
if (best.satisfiable()) {
return best;
} else {
if (state.weight() > best.weight()) {
return state;
} else {
return best;
}
}
}
}Jako nejlepší je tedy vyhodnocen pouze stav, ve kterém je formule splnitelná. Stavy se porovnávají jen na základě váhy. O zvýhodnění splnitelných stavů při prohledávání stavového prostoru jsem se tak snažil v metodě nextState():
delta = (double)state.weight() / newState.weight();
delta2 = (double)state.numOfSatisfiableClauses() / newState.numOfSatisfiableClauses();
delta = (delta + delta2) / 2;
if (!newState.satisfiable() && state.satisfiable()) {
delta = delta * penaltyFactor;
} else if (!state.satisfiable() && newState.satisfiable()){
delta = delta / penaltyFactor;
}
if (delta > 1) {
double r;
r = random.nextDouble();
if (r < Math.exp(-( (delta) / temp))) {
state = newState;
}
} else {
state = newState;
}
return state;Červeně označenou část kódu budu dále označovat jako optimalizaci. V grafech pak rozlišuji Simulované ochlazování s optimalizací a Simulované ochlazovaní. Měření prokázalo, že byla chyba nazývat tuto část kódu optimalizací. O tom ale píši v sekci měření.
Použil jsem tedy poměr vah i splnitelností a do proměnné delta dosazuji jejich průměr, abych zvýhodnil stavy, které nepomáhají při zvýšení váhy, ale pomáhají v cestě k splnitelné formuli. Proměnná penaltyFactor je ten nový parametr, v který jsem vkládal tolik nadějí, co se cesty k splnitelné formuli týče. Z grafů je vidět, že příliš nepomáhá. Díky těmto metodám se začal algoritmus chovat alespoň trochu kontrolovaně a mohl jsem tak přistoupit k vlastnímu měření.
Měření
Měření byla
provedena pomocí knihovní funkce System.nanoTime(),
kterou jazyk Java poskytuje.
A to na stroji s procesorem Core Duo
1.66GHz a operačním systémem GNU/Linux (jádro
2.6.22).
Nebylo započítáváno načítaní
dat ze souboru ani jejich zapisování na výstup.
Každá změřená
časová hodnota v grafu je průměrem měření ze 100
instancí těchto parametrů:
20 proměnných
91 klauzulí
Již tradičně jsem provedl měření v několika iteracích. Měnil jsem vždy hodnotu jednoho parametru a ostatní zachoval, takže jsem potřeboval nějaké rozumné „ostatní“, aby výsledky pro konkrétní parametr dávaly smysl. Sem umísťuji grafy z kola posledního, kdy jsou parametry nastaveny na tyto hodnoty:
počáteční teplota = 1000
konečná teplota = 1
počet kroků = 10000
faktor ochlazování = 0.85
penalizační koeficient = 10
Poznámka
Po změření reakcí algoritmu s optimalizací na změny všech parametrů jsem provedl ta samá měření s vypnutou optimalizací. Chtěl jsem tím demonstrovat, jak efektivní optimalizaci jsem navrhl. Výsledky tohoto druhého měření mne rychle uvedly z omylu. Proto v grafech uvádím oba průběhy.
Počet kroků
Z prvních dvou grafů je jasně vidět, že použití optimalizace nemá smysl. Za mírné zlepšení procenta nalezených řešení platíme vysokou daň v podobě zvýšení časové náročnosti výpočtu. To už je pravděpodobně lepší pustit neoptimalizovaný algoritmus několikrát za sebou.
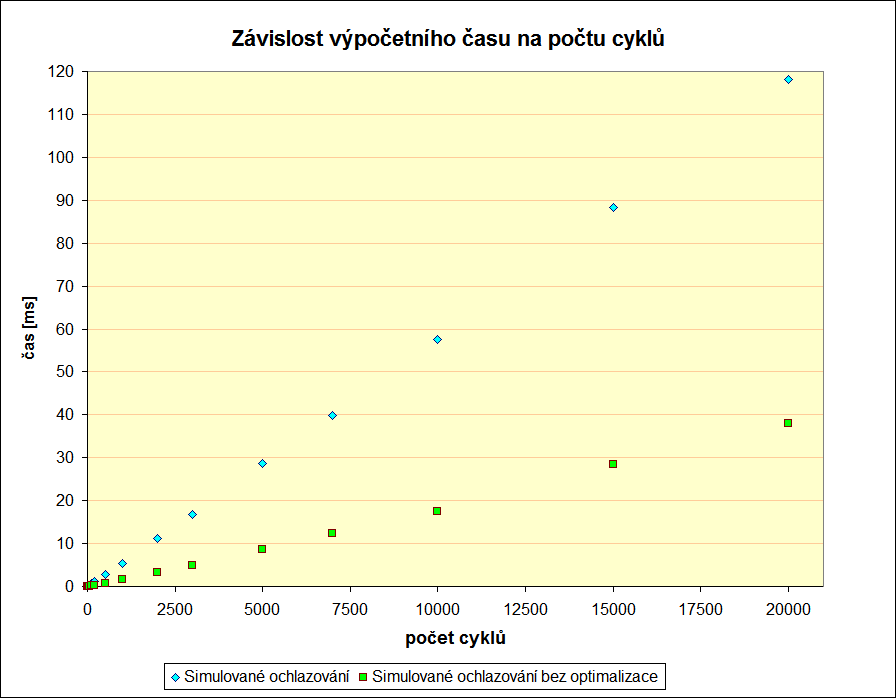
Třetí graf ukazuje, že na průměrnou váhu konečného řešení nemá optimalizace prakticky žádný vliv.

Faktor ochlazování
Hned první graf ukazuje, že optimalizace sice pomáhá ke zvýšení procenta splnitelných řešení, ale tato pomoc se stává téměř zanedbatelnou se zvyšováním faktoru ochazování. Vzhledem k použití randomizace v algoritmu není takovýto výsledek velkým přínosem. Hlavně když vezmeme v úvahu další dva grafy.

Následující dva grafy ukazují, že použití optimalizace je dosti časově náročné a nepřispívá k nalezení stavu s vyšší váhou. Ba právě naopak.
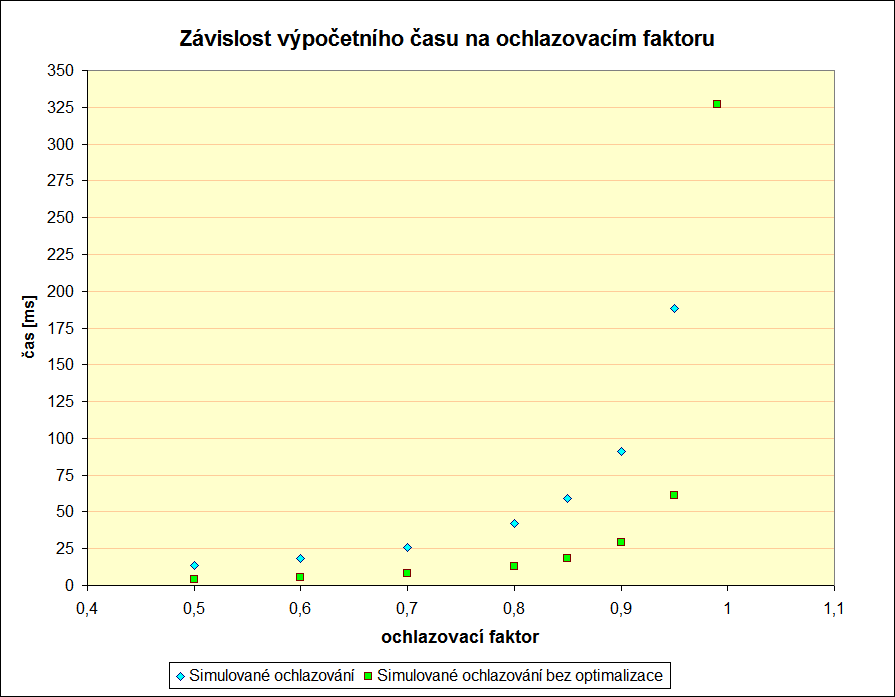

Počáteční teplota
U tohoto parametru můžeme pozorovat jiné závislosti než tomu bylo u problému batohu. První graf nám ukazuje, jakou máme zvolit minimální počáteční teplotu, aby bylo procento úspěšných řešení stabilnější.
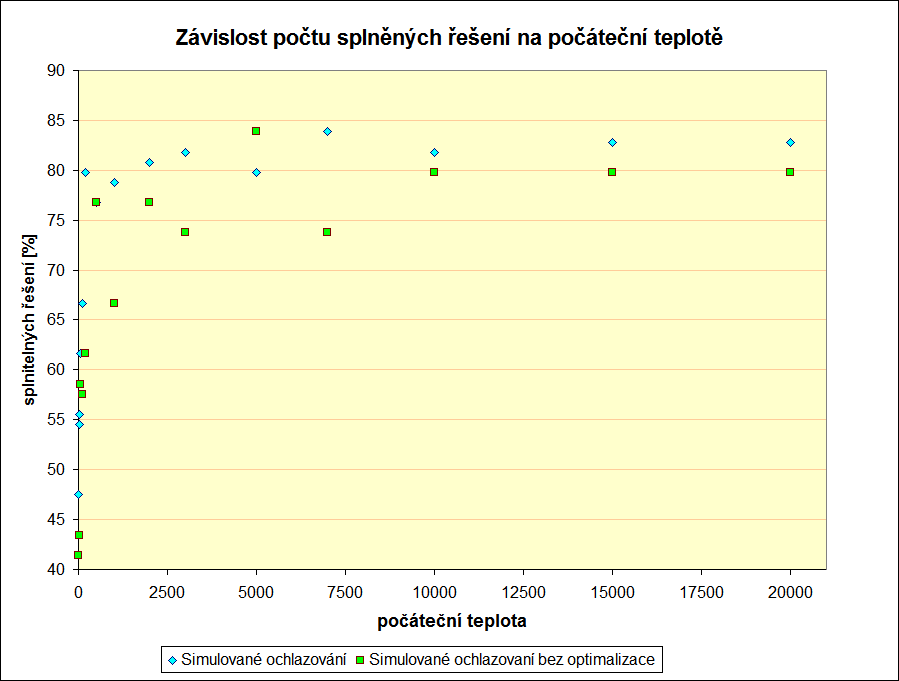
Z dalšího grafu pak vidíme cenu, kterou platíme za zvýšení počáteční teploty. Je zřejmé, že příliš vysoká teplota není vhodná, protože nám stejně nepomůže snížit procento nalezených řešení. Znova tu pozorujeme drastický nárust časové náročnosti algorimtu při použití optimalizace.
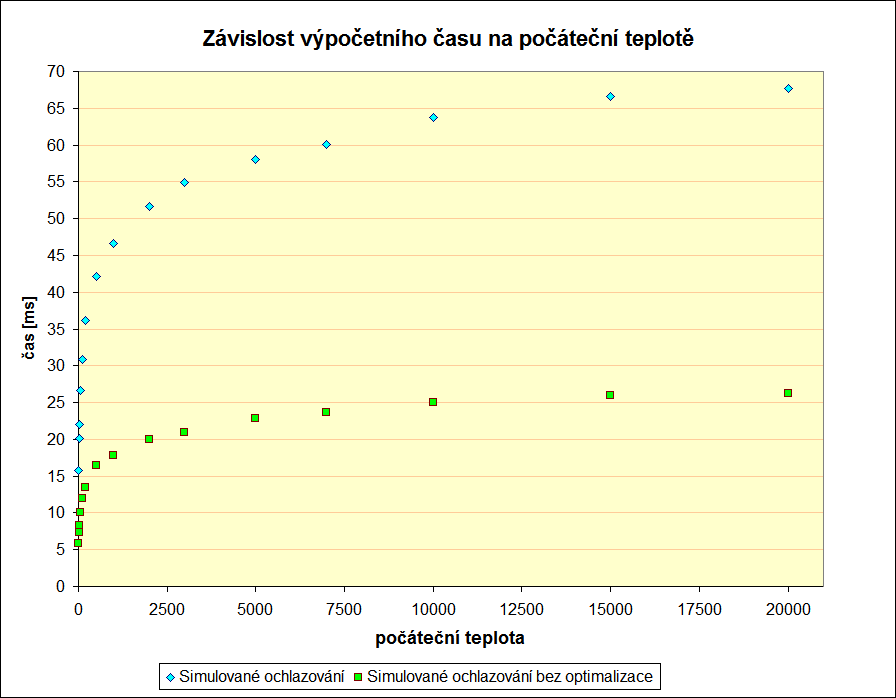
Poslední graf nás utvrdí záměru nevolit příliš vysoké počáteční teploty. Vliv náhody je stále příliš velký na to, aby se nám volba vysoké teploty (např. nad 5000) vyplatila. Rozmístění výsledků optimalizovanéhe verze vzhledem k neoptimalizované považuji za dílo náhody.

Konečná teplota
Z grafů závislostí na konečné teplotě je vidět, že se vyplati zvolit co nejnižší teplotu zmrazení algoritmu, protože jen tam jsou o poznání menší výkyvy ve vahách řešení – jak je vidět z třetího grafu.
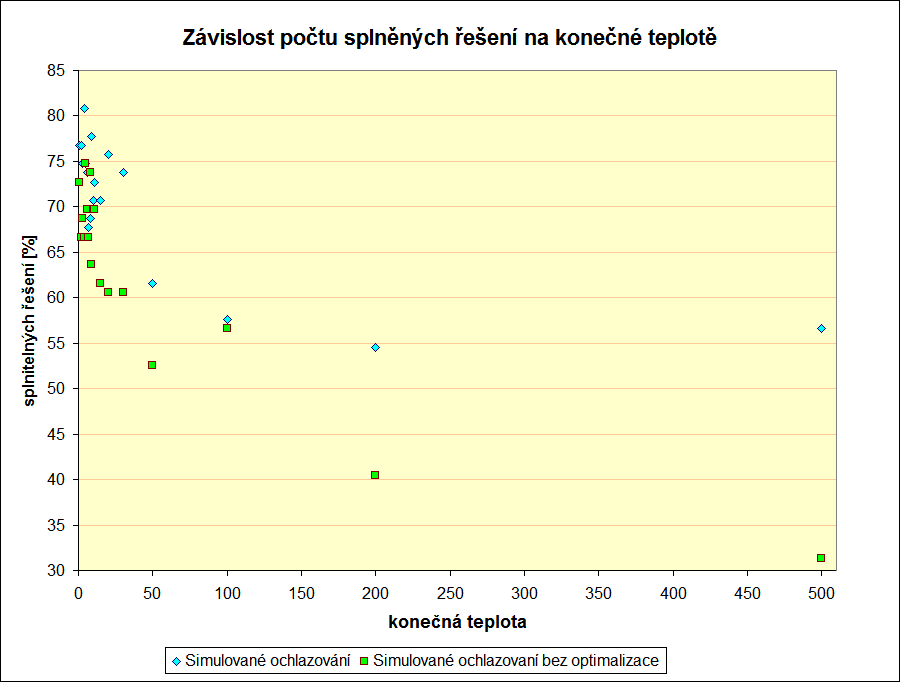
I v tomto případě optimalizace dokázala, že nám předvádí velmi málo muziky za hodně peněz.

U třetího grafu ukazuji jen menší část osy s konečnými teplotami, aby bylo lépe vidět chování algoritmu s konečnou teplotou nastavenou blízko nule.

Optimalizační faktor
Z uvedených grafů je vidět, že algoritmus zadanou úlohu řeší slušně. Jen ta optimalizace, v kterou jsem v kládal naděje, se neosvědčila. Je proto třeba zatlouci poslední hřebíky do rakve mé optimalizace a uvést grafy závislostí na optimalizačním koeficientu. Jak je z následujících tří grafů vidět, tak jakékoliv zlepšení řešení je dílem náhody a nikoliv měřeného koeficientu. Naštěstí se obejdeme i bez něj.


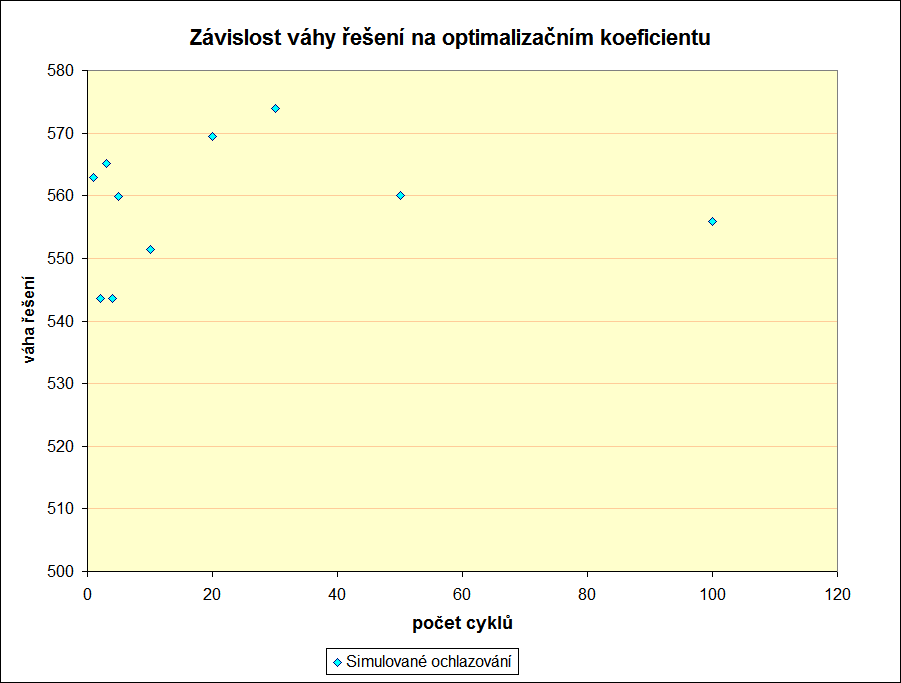
Závěr
Implementace samotného algoritmu není příliš náročná. To samé se však nedá říct o hledání vhodných parametrů. V algoritmu je dvakrát použita randomizace – poprvé při vybírání vhodného souseda, podruhé při rozhodování o tom, jestli se budeme zabývat horším stavem než současným. Změny v parametrech se tak navenek projeví až při opakovaném měření většího počtu instancí s mnoha různými hodnotami zkoumaného parametru. To činí celý proces hledání zdlouhavým. Má snaha o další optimalizaci algoritmu ztroskotala - jak je ostatně vidět z grafů. Kupříkladu počty cyklů a faktor ochlazování. Zvýšení těchto parametru prodlužuje čas potřebný k nalezení vhodného řešení a pokud použijeme optimalizaci, tak je čas i dvojnásobně delší. Optimalizaci tudíž bylo nutné testovat při parametrech nastavených na vysoké hodnoty, aby se rozdíl projevil a vyloučil se vliv náhody. A to je časově velmi náročné. Při použití algoritmu bez optimalizace dostaneme výsledek instance o 20ti proměnných a 91klauzulích za cca 20ms s pravděpodobností splnitelnosti formule kolem 80%.